We extract data
from books & catalogs.
You send us the printed books or catalogs, we extract the data and images and deliver a complete database. Works for auction catalogs, historical data and more.

What kind of data can you extract?

Photos
It can be anything. Images of stamps, artwork, vintage products or people. We extract each image and connect it to its description.

Text
Each piece of text can be independently extracted and connected to its corresponding photo. We can also extract names, dates, locations which are inside.

Tables
Sometimes the tables are more obvious, sometimes less. We extract them, group them together and deliver a full and correct database which you can import.
Why digitize your auction catalogs?
Instant search.
You can find any item in the entire database just by using keywords. No more browsing in printed catalogs from the archive.
Find visually similar items.
Many items can't be found by a specific keyword, but using neural networks, we can tell you which are the items that are identical or similar to it.
Start selling online.
Once you have your database of items and their respective images it is easy to publish them on your website to create virtual auctions or have customers ask about them.
Just share them.
Digital versions of catalogs are easy to share and easy to browse through. We provide you with PDF files which you can share with your customers.
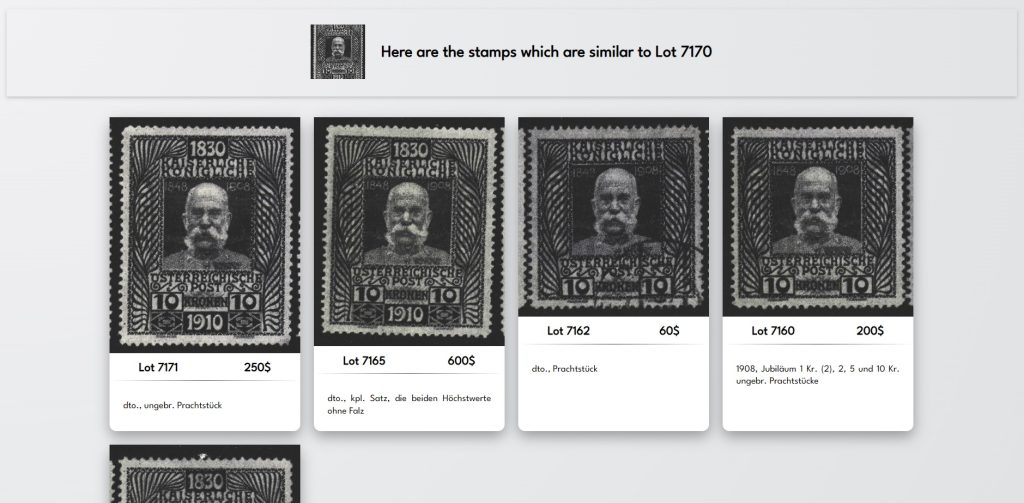
Find visually similar items using neural networks.
Here’s a demo of how our algorithm found every identical stamp in the same auction catalog to the one that we provided in the top-left corner. Notice that some have stamps on them, some don’t but the software still managed to find them. This would take ages if you had to browse through an entire archive of catalogs.
Frequent questions
We can literally extract the data from anything from auction catalogs for stamps, coins, banknotes, luxury items, art but also catalogs raisonee. The whole idea is for them to follow a logical and coherent structure.
This is a tricky question. We can extract relevant information from structured data like tables but we have had success in extracting information from unstructured data like raw paragraphs where key pieces of info were hiding.
We do evaluate on a case-by-case basis do determine the type of data which needs to be processed. You send us your product catalogs and we'll evaluate if we can extract it or not.
The document data extraction service that we provide is semi-automated which means that at its core we use algorithms to pull out the raw information but we hire entire data teams to validate and correct the information.
For every project we build a custom data extraction tool so that we can increase the document processing speed as much as possible. We also take into account extracting rules that you may want like replacing certain words or discarding some data.
The price for extracting data varies mostly depending on how easy it is to get the data out and how much validation is needed.
That being said, with every project, our goal is to find the fastest and most efficient data flow so that data processing is automated as much as possible while keeping manual data entry and validation at a minimum.
But hey, it's free to request a quote from us for your project.
You provide us with the printed materials be it catalogs, books, library catalogs, any kind of data catalogs. You send them to our HQ via your courrier of choice. These will be our data sources.
We will deliver complete databases which contain the data together with the images linked up to their corresponding description. So this can be anything from a CSV file, Excel XLSX sheet, an SQL file to import into a relational database or a format of your choice.
We can also import the relevant data into a simple search platform which allows you to search through the records easily. There is also the option for our data engineers to provide you with the similarity data for each image so that you know exactly which items are similar to which. You also receive the scanned documents from which we extracted the data of course.
